기업 SEMES와의 연계프로젝트였던 <AI를 활용한 OHT물류데이터 로그분석 시스템>을 개발하며 발생했던 문제중 하나였던 "느린 집계속도" 문제를 해결했던 방법에 대해 포스팅 해보려고 한다.
(해당 프로젝트의 내용, 그리고 아키텍처 설계에 관해선 이전 포스팅에서 볼 수 있다.)
프로젝트의 초기 설정을 간단히 보고 가자면, AnyLogic이라는 시뮬레이션 툴이 OHT 물류 데이터를 생산한다. 이는 그대로 RDB에 저장되며, Spring에서 select 쿼리를 날림으로써 데이터를 집계하게 된다.

그리고 바로 여기서 문제가 발생한다.
AnyLogic은 시간당 10만, 즉 하루 300만개의 데이터를 생산하는데, 실제 시스템에선 한달이 넘는 기간에 대한 요청이 들어올 수 있다. 이경우 select쿼리가 수행되는데 아주 오랜 시간이 걸린다.
RDB의 Full-Scan
해결방법을 알아보기 전에, 이유를 간단히 정리해봤다. 쿼리가 느린 이유는 요청 기간에 대한 모든 데이터들을 Full-Scan하기 때문이다. 물류데이터 테이블에서 PK는 auto_increment 하나였고, 집계의 기준이 되는 OHT ID나 OHT의 상탯값과 같은 컬럼들은 인덱싱되어있지 않았다. 이경우 조건에 맞는 row를 찾기위해 DBMS는 모든행을 스캔한다. 그렇기때문에 속도가 느릴수밖에 없는것이다.
이를 해결하기 위해선 타 컬럼에 대한 인덱스를 생성하는 방법이 있지만, 현재 프로젝트에선 하루 300만개의 데이터가 생성된다. 즉 전통적 RDBMS에서 처리하기엔 부담이 있었다. 기본적으로 PK를 제외한 인덱스들은 논클러스터드 인덱스이기 때문에, 인덱스가 많아질수록 생성 및 업데이트가 느려진다. 실제 요구사항에선 훨씬 많은 컬럼들이 집계 기준이 되었기 떄문에 이 방법은 부적합하다고 느껴졌다.
ELK 스택의 도입
그래서 우리는 ELK를 도입하게 되었다. Elasticsearch는 역인덱스 구조를 가지고 있어 검색 최적화 및 쓰기 성능이 뛰어나다는 큰 장점이 있었다. 데이터 삽입시에도 비교적 성능저하가 적다. 또한 샤딩을 통해 수평적 확장을 간편하게 지원한다. 차후 실제 기업에 이 시스템이 도입됐을경우, 엄청나게 큰 데이터를 저장하기에 알맞은 확장성을 가진다.
부가적인 장점도 있었다. RDBMS에선 데이터가 잘 처리되었는지 확인하기 위해 Select를 수행하면, 너무 많은 데이터로 인해 시스템 자체가 매우 느려지거나 강제종료 되는 문제가 있었는데, ELK의 경우 Kibana를 통해서 실시간으로 데이터를 시각화해 확인할 수 있었다. 대용량 데이터를 다루는데 적합한 툴이라는걸 여실히 느낄 수 있었다.
ELK는 다음과 같은 아키텍처로 도입했다.

1. LogStash가 MySQL에 저장된 데이터를 5분마다 조회하여 Elasticsearch에 데이터를 복제한다.
2. 클라이언트에서 집계를 요청하면, Spring은 Elasticsearch 서버로 API를 통해 집계쿼리를 전송한다.
3. Elasticsearch의 응답을 Spring에서 적절히 변환하여 응답한다.
그리고 이러한 아키텍처의 구현 과정에서, (1) 단순히 ELK를 도입할 뿐 아니라 Index를 활용해 좀 더 빠른 검색 방법을 고안했고, (2) 복잡한 쿼리를 생산성있게 작성할 수 있는 유틸을 작성했다. 이제 이러한 부분에 대해 설명해 보고자 한다.
효율적으로 개선하기(1) : INDEX의 분리
.현재 클라이언트의 요청들은 기본적으로 "기간값"을 포함하고 있었기 때문에, INDEX를 날짜별로 분리하는 방법을 통해 검색 쿼리 성능을 높이고자 하였다. Logstash가 Elasticsearch서버로 데이터를 전송할때, 날짜컬럼을 트래킹함으로써 일자를 기준으로 데이터를 분리했다.
input {
jdbc {
jdbc_driver_library => "/usr/share/logstash/logstash-core/lib/jars/mysql-connector-j
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://{DB주소}"
jdbc_user => "id"
jdbc_password => "pw"
schedule => "*/1 * * * * *"
statement => "select * from log where curr_time > :sql_last_value"
**tracking_column => "curr_time"**
use_column_value => true
codec => plain {
charset=>"UTF-8"
}
}
#..생략
output {
elasticsearch {
hosts => "elasticsearch:9200"
user => "elastic"
**index => "semento-mysql-logs-%{formatted_curr_date}"** #영국시간을 한국시간으로 바꾼변수
password => "pw"
document_id => "%{doc_id}"
}
}
이렇게 curr_time을 트래킹하고, index명을 셋팅해주면, Kibana를 통해 다음과 같이 일별로 분리된 INDEX들을 확인할 수 있다.
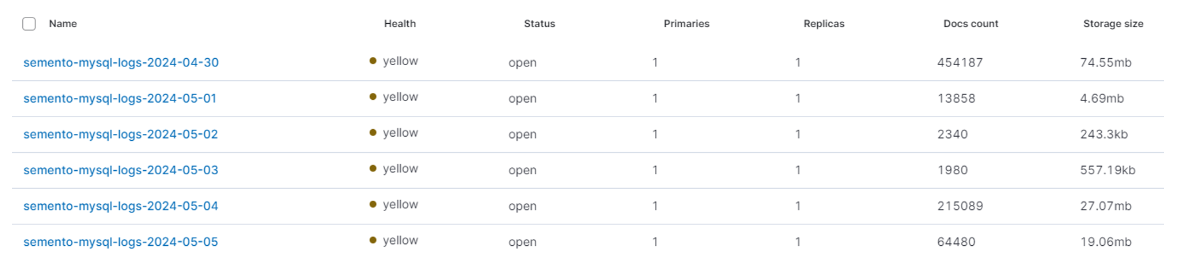
Elasticsearch API를 통해 검색쿼리를 전송할때, 검색할 INDEX 범위가 축소되므로 검색속도가 크게 개선된다. 또한 Elasticsearch는 클러스터의 노드들이 병렬로 쿼리를 처리할 수 있으므로, 클러스터 리소스를 효과적으로 사용할 수 있었다.
효율적으로 개선하기(2) : 복잡한 쿼리를 생산성있게 작성하는 Util함수 만들기
이제 Spring단에서 Elasticsearch에 집계API를 요청하는 코드를 작성해야했다. 그러나 사소한 문제가 있었다. 개발 초기엔 Spring-Data-Elasticsearch라는 라이브러리를 통해 간단하게 집계API를 만드려고 했다.(JPA에 익숙해서 금방 익힐 수 있었다)
그러나 회의과정에서 프로젝트 요구사항이 더 복잡해짐에 따라, 집계쿼리도 굉장히 복잡해졌다. Spring-Data-Elasticsearch는 의존성 버전 업데이트도 느리고, 복잡한 쿼리에 대한 작성효율도 굉장히 떨어졌기에, 더이상 프로젝트에 적합한 라이브러리가 아니었다.
결론적으로, 러닝커브가 높긴 하지만 쿼리의 커스텀이 자유로운 High-Level-Client라는 라이브러리를 선택했다. 사용법을 간단히 요약하면, 각 집계함수에 대한 클래스가 선언되어있어, 이를 정의하고 최종 쿼리로 조립한 뒤 요청하면 되는 형태였다.
그리고 몇가지 API를 짜고 난 뒤, 팀원들의 API와 함께 비교해보니, 공통적인 작업들이 눈에 띄었다. BoolQuery와 TermsAggregation, 검색할 인덱스 범위 설정, 완성된 검색쿼리를 전송하는 요청로직 등이 있었다. 나는 이러한 공통작업들의 반복을 막고, 생산성있게 API를 만들 수 있도록 Util 함수를 작성했다. 특히 쿼리를 전송하는 sendEsQuery()메소드의 경우, 집계에 따라 파라미터가 달라지므로 가변인자와 오버로딩을 적극 활용해 간단히 사용할 수 있게 했다.
/**
* Elasticsearch 쿼리를 전송하는 일반화된 메소드
* @author
* @param startTime 시작시간
* @param endTime 종료시간
* @param boolQueryBuilder 조건
* @param aggregations 집계조건들
* @return 검색 응답
* @throws IOException 네트워크 또는 ES 서버에서 예외 발생 시
*/
public SearchResponse sendEsQuery(LocalDateTime startTime, LocalDateTime endTime, BoolQueryBuilder boolQueryBuilder, AggregationBuilder... aggregations) throws IOException {
//인덱스 리스트 생성
String[] indexArray = getIndexNameArray(startTime, endTime);
// index가 존재하지 않으면 생성하기
for (String indexName : indexArray) {
ensureIndexExists(indexName);
}
//시간필터 생성
RangeQueryBuilder timeFilter = generatedTimeFilter(startTime, endTime);
boolQueryBuilder.must(timeFilter);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder()
.query(boolQueryBuilder)
.size(0); // 문서 반환 없이 집계 결과만 반환
for(AggregationBuilder aggregation : aggregations) searchSourceBuilder.aggregation(aggregation);
SearchRequest searchRequest = new SearchRequest(indexArray);
searchRequest.source(searchSourceBuilder);
log.debug("[ES request] : "+ startTime + " =>" + endTime);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
return searchResponse;
}
/**
* Elasticsearch 쿼리를 전송하는 일반화된 메소드
* @author
* @param startTime 검색시작시간
* @param endTime 검색끝시간
* @param aggregations 집계조건들
* @return 검색 응답
* @throws IOException 네트워크 또는 ES 서버에서 예외 발생 시
*/
public SearchResponse sendEsQuery(LocalDateTime startTime, LocalDateTime endTime, AggregationBuilder... aggregations) throws IOException {
//생략
위와같이 Util함수를 를 작성함으로써, Service단에선 아래와 같이 집계 클래스만 만들어서 조립한 뒤, Util 메소드를 활용해 중복코드 양을 획기적으로 줄이고, 개발생산성을 높일 수 있었다.
/** 개별 OHT 작업별로 분류
* @param DateAndOhtRequest 검색시간과 oht-id
* @return ClassificationLogResponse 검색 응답
* @author
*/
public ClassificationLogResponse getClassificationLog(DateAndOhtRequest dateAndOht) throws IOException {
LocalDateTime startTime = dateAndOht.getStartDate();
LocalDateTime endTime = dateAndOht.getEndDate();
Long ohtId = dateAndOht.getOhtId();
//==bool Query==
ExistsQueryBuilder existsQuery = QueryBuilders.existsQuery("start_time");
TermQueryBuilder termQuery = QueryBuilders.termQuery("oht_id", ohtId);
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery()
.must(existsQuery)
.must(termQuery);
//==TermsAggregationBuilder==
TermsAggregationBuilder byStartTime = AggregationBuilders.terms("by_start_time")
.field("start_time")
.size(10000)
.order(BucketOrder.key(true));
MaxAggregationBuilder maxCurrTime = AggregationBuilders.max("max_curr_time").field("curr_time");
TermsAggregationBuilder errors = AggregationBuilders.terms("errors")
.field("error")
.size(10000)
.order(BucketOrder.key(true));
AvgAggregationBuilder averageSpeed = AggregationBuilders.avg("average_speed").field("speed");
MaxAggregationBuilder maxIsFail = AggregationBuilders.max("max_is_fail").field("is_fail");
byStartTime.subAggregation(maxCurrTime)
.subAggregation(errors)
.subAggregation(averageSpeed)
.subAggregation(maxIsFail);
//요청 및 응답받음
SearchResponse searchResponse = elasticsearchQueryUtil.sendEsQuery(startTime, endTime,
boolQuery, byStartTime);
//생략...
return ClassificationLogResponse.builder().totalCnt(terms.getBuckets().size()).logPerWork(logPerWorkList).build();
}
(CF) 기존 SQL 지식을 활용하여 Elasticsearch API 빠르게 학습하기
이 내용은 아주 간단한 참고사항이다. 당시 우리팀의 경우 MySQL과 같은 일반 SQL엔 익숙했지만, Elasticsearch API에 익숙하지 않아 학습에 어려움을 겪었는데, 그런분들을 위한 팁이다.
기존 지식을 활용하여 Elasticsearch 쿼리를 빠르게 학습하기
데이터는 단지 <어떤 시간에 어떤 OHT가 어떤 상태로 어떤 위치에 있는지>를 정의하고 있다.
따라서 시간대별 작업량 평균 비교, 개별 OHT의 작업량과 전체 OHT 평균작업량 비교, DeadLine을 넘은 작업량 등의 요구사항을 충족하려면 굉장히 복잡한 쿼리가 필요했다.
팀원 모두가 초심자였던 상황에서, 이 러닝커브를 빠르게 돌파하기 위해 다음과같은 개발과정을 도입했다.
(1) MySQL로 원하는 집계쿼리를 작성한다.
SELECT start_time
FROM log
WHERE oht_id = 2609
AND curr_time BETWEEN '2023-01-01 00:00:00' AND '2023-01-01 23:59:59'
AND start_time IS NOT NULL
GROUP BY start_time(2) Elasticsearch 공식문서를 참고하여, 같은 기능의 Elasticsearch쿼리를 작성한다.
POST /semento-mysql-logs-2023-01-01/_search
{
"size": 0, // 검색 결과로 문서를 반환하지 않고 집계만 수행
"query": {
"bool": {
"must": [
{
"term": {
"oht_id": 2609
}
},
{
"range": {
"curr_time": {
"from": "2023-01-01T00:00:00+09:00",
"to": "2023-01-01T23:59:59+09:00",
"include_lower": true,
"include_upper": true
}
}
},
{
"exists": {
"field": "start_time"
}
}
]
}
},
"aggs": {
"by_start_time": {
"terms": {
"field": "start_time",
"size": 10000,
"order": { "_key": "asc" }
},
"aggs": {
"max_curr_time": {
"max": {
"field": "curr_time"
}
},
"errors": {
"terms": {
"field": "error",
"size": 10000,
"order": { "_key": "asc" }
}
},
"average_speed": {
"avg": {
"field": "speed"
}
},
"max_is_fail": {
"max": {
"field": "is_fail"
}
}
}
}
}
}
(3) 두 쿼리의 결과를 크로스체크하여 정확성을 검증한다.
sql 쿼리를 먼저 작성함으로서 조건을 빠트리지 않을 수 있었고, Elasticsearch의 집계 쿼리를 빠르게 익힐 수 있었으며, 3번과정을 통해 올바른 쿼리를 작성했는지도 확인할 수 있어 작업효율이 올라갔다.
위 과정을 통해 아래와 같이 한달단위의 데이터도 빠르게 집계할 수 있는 API를 완성할 수 있었다.

이러한 문제해결 경험을 통해서 얻은 가장 큰 수확은 "문제를 해결하기 위해 개선할 부분을 고민하고, 그것이 설령 처음 해보는 것일지라도 도전하는 경험" 이였다.
본문엔 자세히 적지 않았지만, 고민 과정에서 프로메테우스 등 다양한 후보군을 조사하고, 그중에서 어떤 기술이 가장 적합한 해결책인지 고민했었다. 이를 통해 적합한 기술을 선택할 줄 아는, 개발자로서의 시야를 가지게 되었다고 생각한다.
또한 처음 경험하는 기술일지라도, 기존의 지식을 활용해 빠르게 적응하고 개발 할 수 있다는것도 깨달았고 자신감이 생겼다. 위 팁에 작성한 방법을 통해(백엔드 팀원 모두가 ELK를 처음 사용하는 것임에도 불구하고) 기존의 MySQL 쿼리를 완전히 대체해 도입 하는데엔 단 일주일 밖에 걸리지 않았다! 특히 개발이라는 학문은, 연속적으로 발전되는 기술들이 많기에, 현재 내가 가진 자원을 기반으로 새로운 기술을 학습하는것이 깊이있고 빠르게 학습할 수 있는 방법임을 체감한 것 같다.
깃허브 리포지토리는 여기에서 볼 수 있다.
'프로젝트 > SEMENTO' 카테고리의 다른 글
| 대용량 데이터 집계 아키텍처 설계 (6) | 2024.11.18 |
|---|