SSAFY에서 좋은 기회로 기업 SEMES와의 연계프로젝트를 진행했었다.
당시 전달받은 주제는 <AI를 활용한 OHT 물류데이터 분석 시스템>이었다. 간단하게 설명하자면, OHT라는 반도체 운송장비가 일을 하며 만드는 대용량 로그를 직접 학습시킨 AI를 통해 분석한다. 이를통해 단순 운송 로그만으로도 몇시에 정체가 일어났는지, 그리고 그 원인은 무엇인지 쉽게 알 수 있게 해주는 프로젝트다.
나는 이 프로젝트에서 AI를 제외한 모든 역할, 즉 백엔드/프론트엔드/인프라/디자인을 담당했고, 이과정에서 가장 신경썼던 부분중 하나가 바로 오늘의 주제, "아키텍처 설계" 이다.
최종적인 아키텍처 설계도는 몇가지 문제상황을 마주치면서 크게 수정되었다, 자세한 내용은 다음과 같다.
1. AnyLogic 시뮬레이터로 발생하는 실시간 데이터

보안상 문제로 직접 공장 시뮬레이션을 제작해서 데이터를 수집해야했다. 그리고 이는 컨설턴트님의 조언 하에 'AnyLogic'이라는 Java 기반 시뮬레이션 툴을 사용해서 운송 로그를 만들어낼 수 있었다.
(첨언하자면, AnyLogic은 국내 자료가 별로 없고, 해외자료도 많지 않은 편이라서 개발에 큰 어려움을 겪었었다. 만약 이 툴을 사용하려고 하는 분들이 있다면.. 기본적인 조작방식을 익히고, AnyLogic 클라우드에서 비슷한 시뮬레이션을 찾아 공식문서를 토대로 학습하길 바란다. 이를통해 3인이서 단 2주만에 완성할 수 있었다!)
만들어낸 데이터를 DB에 저장해야했기 떄문에, 개발 초반에는 AnyLogic 내부에서 제공하는 DB에 저장한 뒤, 데이터를 엑셀파일로 export하고 MySQL에 import하는 형태로 사용했다. 실제 공장에서도 데이터를 저장하는 중앙 서버가 따로 있기에, 원하는 데이터를 뽑아 우리 시스템에 적용하는 방식을 고안한것이다.
다만 내부DB 성능이 좋지않아 데이터가 조금만 많아져도 프로그램이 다운되기 일쑤였다. 그러나 AI학습에 많은 데이터가 필요했으므로 최대시간까지 돌려야만 했고, 기존 방식의 문제점이 여실히 느껴졌다. (엑셀파일의 보관문제도 있었다.)
이때 기발한 아이디어가 하나 떠올랐는데, 바로 JDBC였다! 외부DB를 직접 연결하는 기능이 없어 문제였는데, 자바 기반의 툴이니까 내부 로직을 통해 JDBC를 임포트해 사용할 수 있었다. 이를 통해서 AnyLogic => MySQL로 바로 데이터를 전송하는 아키텍처를 설계할 수 있었다.
2. RDB의 너무 느린 집계속도
그러나 이 RDB가 만능 해결사는 되지 못했다. 또다른 문제가 백엔드 개발중에 발생했다.
시뮬레이션의 OHT들은 1초마다 상태로그를 만들었다. 그리고 위 시뮬레이션에서 OHT의 총 갯수는 30개로, 하루 1억개가 넘는 데이터를 저장하고 있었다.
여기서 문제가 발생했는데, SEMENTO 프로젝트에서는 대시보드 등 다양한 집계 API가 필요했다.

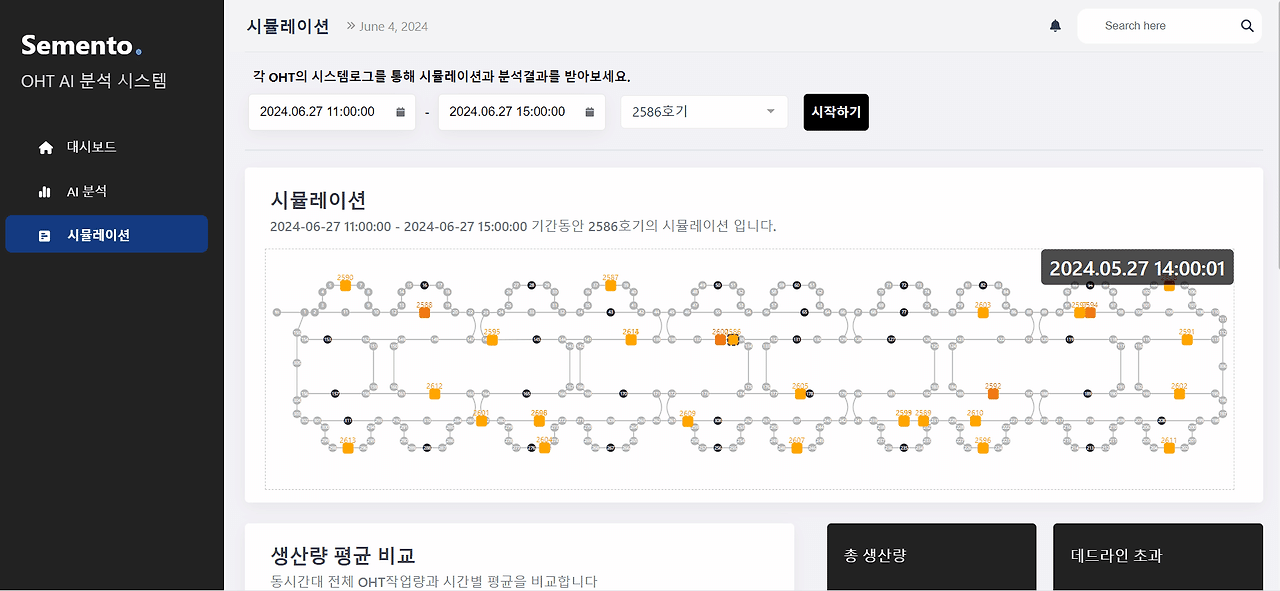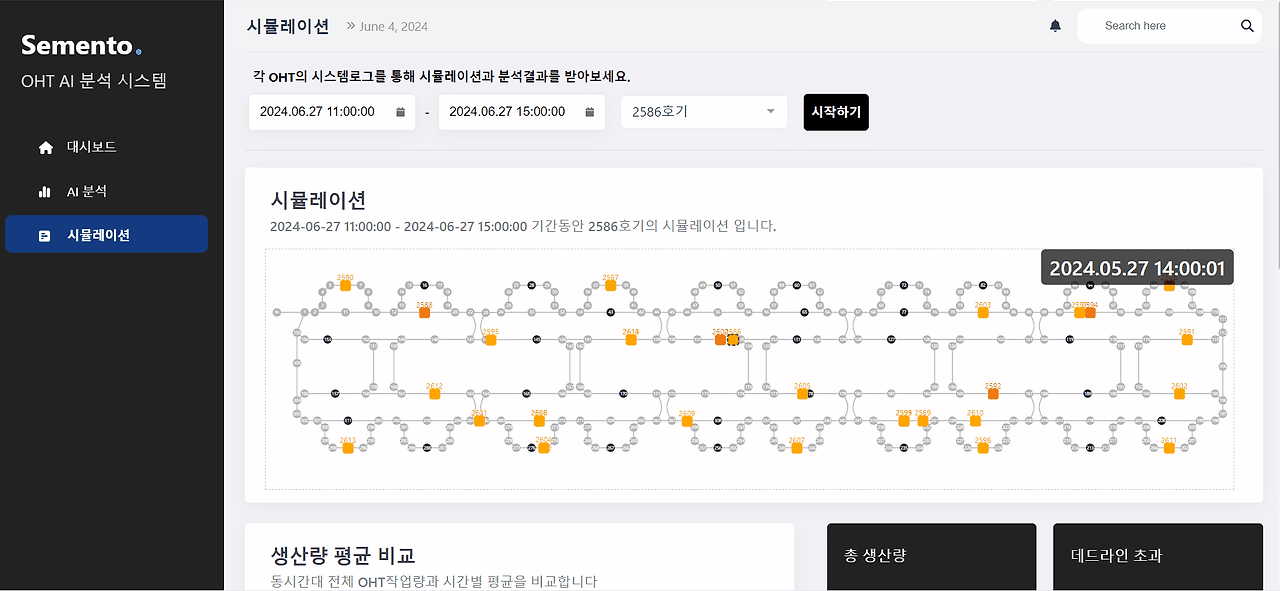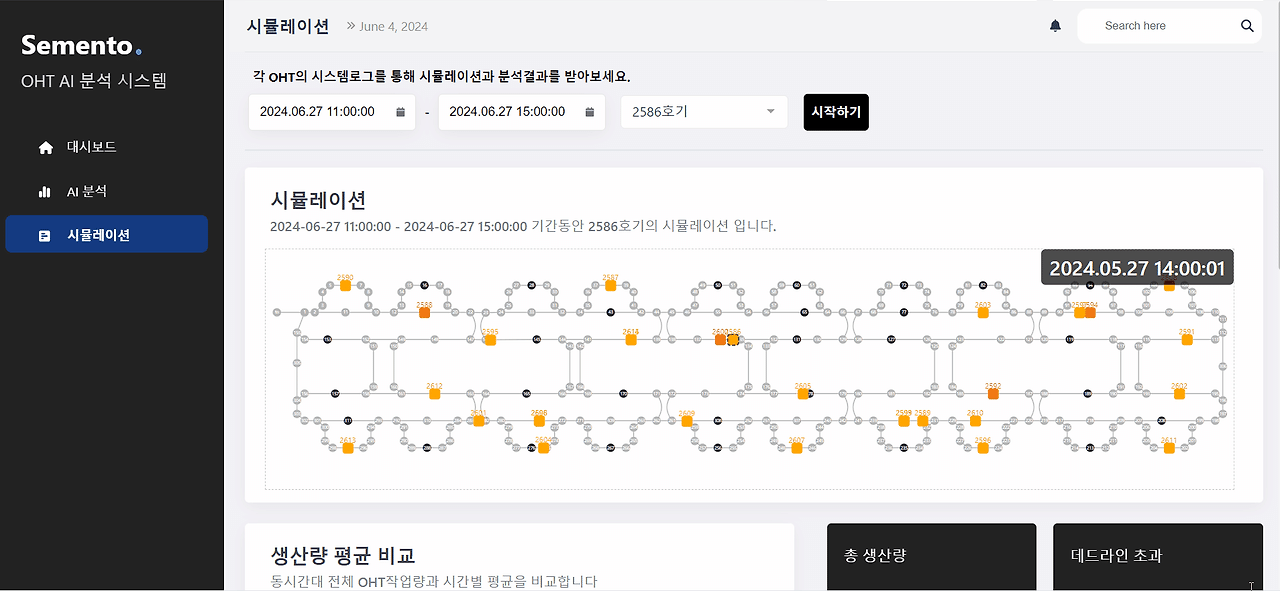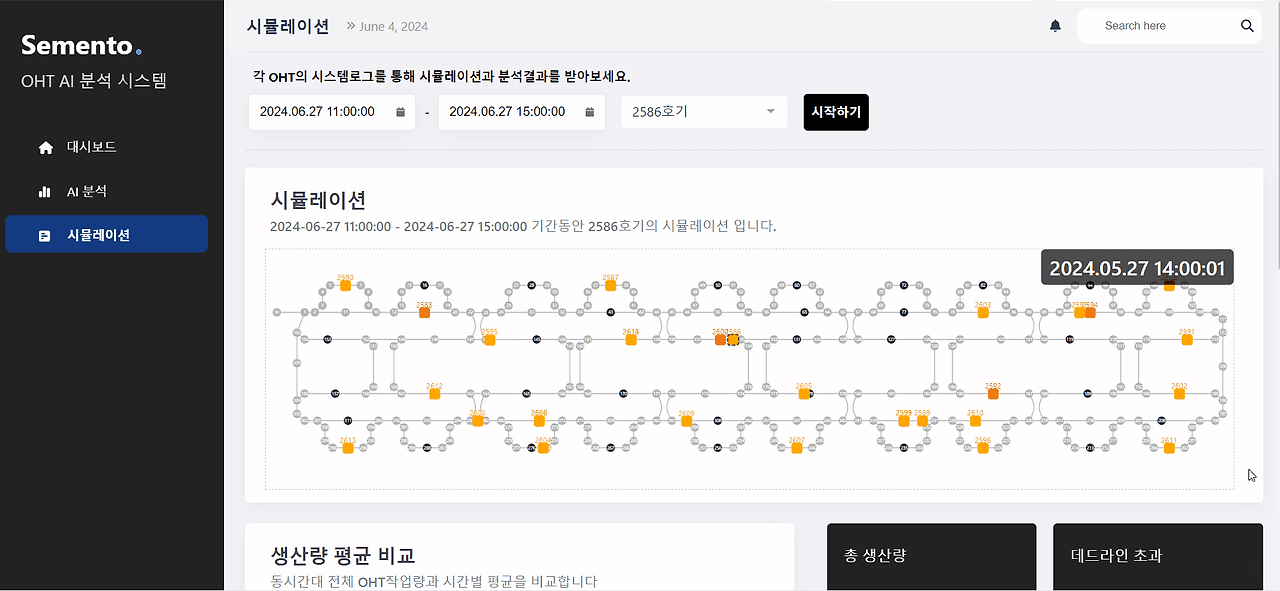
그런데 하루만해도 1억개의 데이터를 full-scan해야 하는데 위와같이 특정 기간, 또는 월별 데이터를 집계해야한다면?
너무 느린 집계속도를 보일것이다!
그래서 해결법을 생각해본 결과, ELK의 도입을 떠올리게 되었다.
Elasticsearch는 역인덱스 구조 덕분에 굉장히 빠른 검색결과를 제공하는데, 우리 프로젝트에 굉장히 적합한 기술이라는 생각이 들었다.
LogStash를 활용해서 데이터를 Elasticsearch로 전송하고, Spring단에선 API요청을 통해 집계결과를 제공받으면 되는것이다.
아키텍처 설계
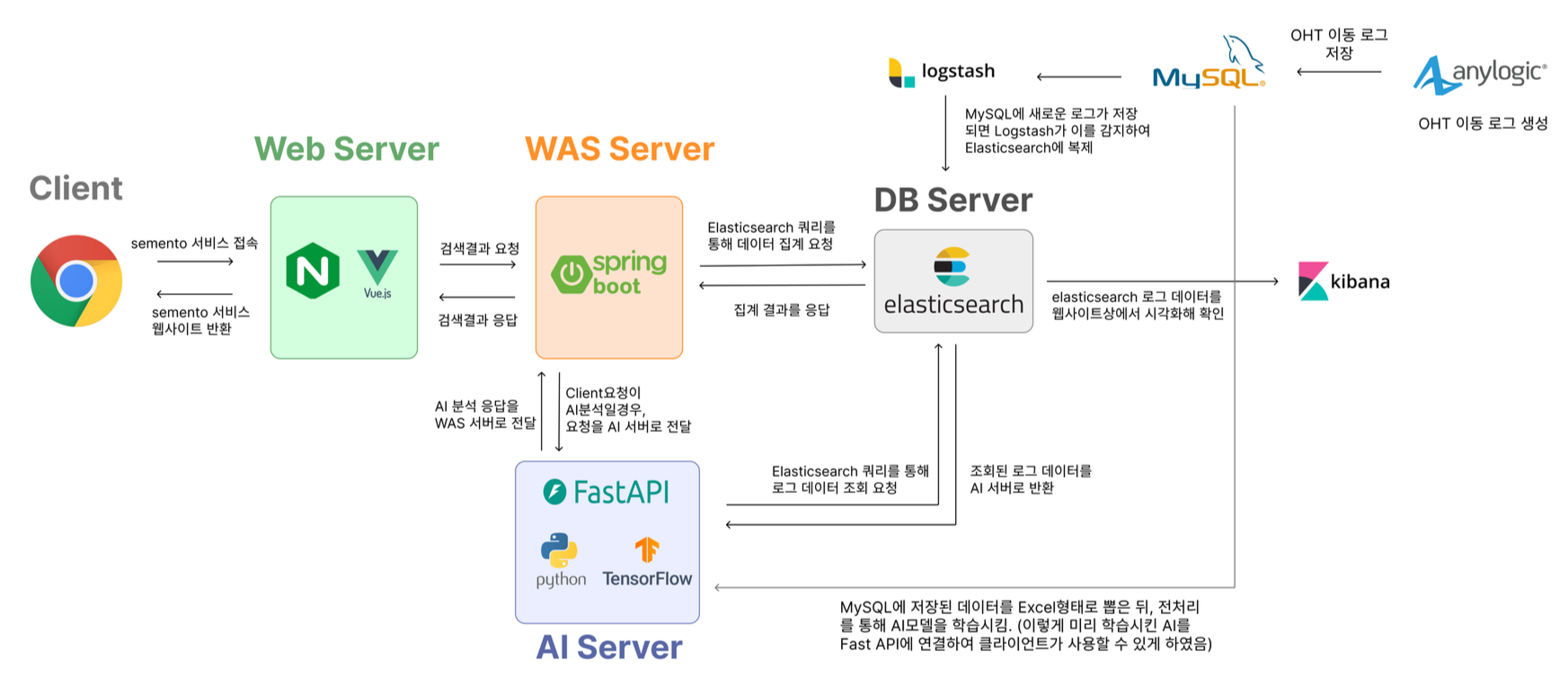
결과적으로, 위와같은 방식을 통해서 구조화 하게 되었다.
사용자가 할 수 있는 요청은 대시보드와 같은 Spring/ELK와 통신하는 요청이 있고, AI분석결과를 검색하는 요청도 있다.
이때 후자 요청의 경우, AI서버로 바로 요청 할 수도 있지만 그렇게 하지 않았다. 그 이유는 Spring으로 프록시처럼 연결하는것이 클라이언트단에서도 훨씬 간결하기도 하고, 분석결과를 찾음과 동시에 대용량 로그까지 응답해주는건 AI서버의 부담이 너무 컸기 때문이다. 따라서 AI는 데이터를 분석한 뒤 결과데이터의 기간을 응답하고, Spring에서 데이터를 찾는 역할을 진행했다. 이렇게 Spring과 AI서버가 역할을 분담하게 함으로써 오버헤드를 줄인 아키텍처를 만들었다.
설명을 제거한 실제 아키텍처는 이렇다.
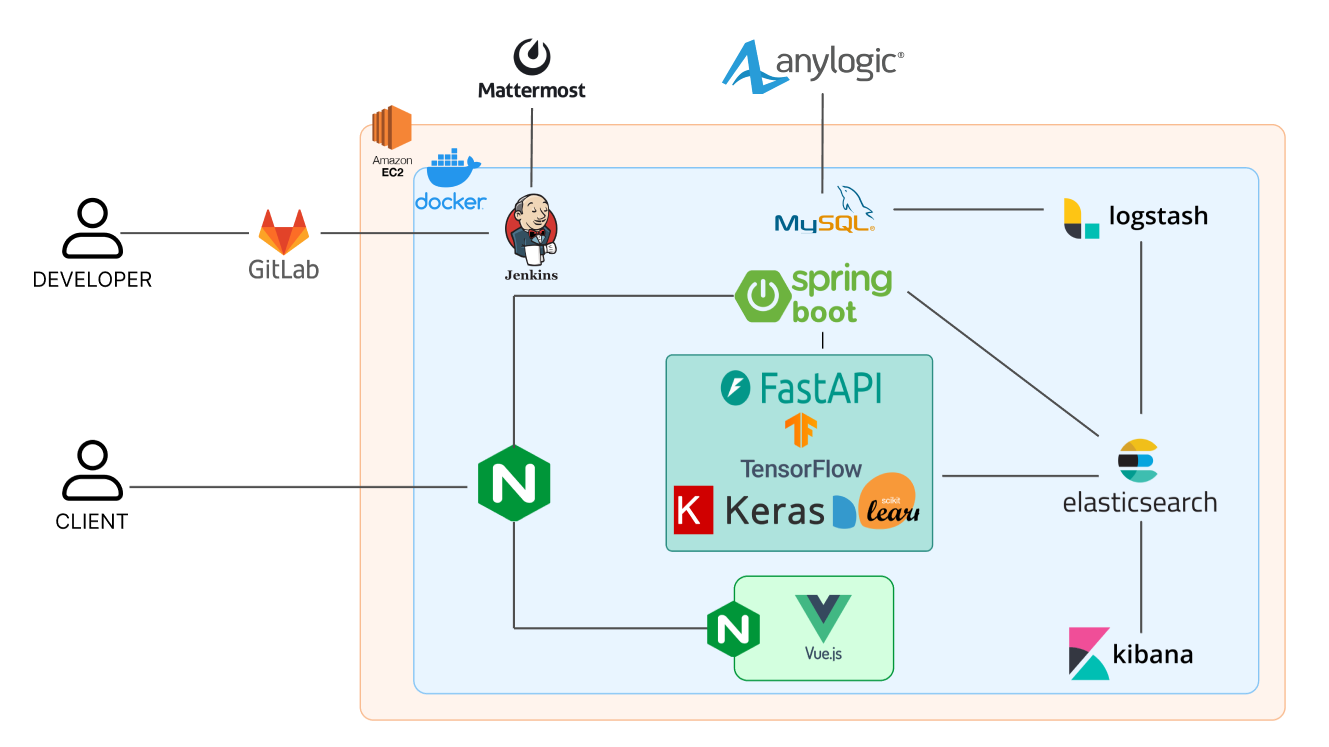
프로젝트 깃허브는 여기서 볼 수 있다!
'프로젝트 > SEMENTO' 카테고리의 다른 글
| 대용량 데이터의 느린 집계속도 문제 ELK로 해결하기 (6) | 2024.11.19 |
|---|