빼곡이 서비스를 시작한지 어느덧 5개월이 되어간다.
그리고 이렇게 프로덕션 서버를 운영하면서, 무중단 배포의 중요성을 느끼게 되었다.
사실 개발단계에서는 배포하느라 서비스가 중단되더라도, 그걸 FE개발자가 그걸 사용중인게 아닌이상 문제될게 전혀없었다.
그런데 프로덕션에서는 다르다. 자잘한 에러나 보완을 하느라 코드를 커밋하는일이 발생하는데, 그때마다 서비스가 멈추면 사용자들은 큰 불편을 겪을것이다. 불안정한 서비스라고 느끼고 탈퇴할수도 있고 ㅜㅜ
그래서 무중단 배포 도입의 필요성을 크게 느꼈고, 여러 기법들을 공부하며 실제로 도입까지 완료했다.
이번 포스팅은 그 여정을 담아보았다.
무중단 배포?
말 그대로 서비스의 중단 없이 새 버전을 배포하는 개념이다.
무중단배포를 도입하지 않은 일반적인 CI/CD의 경우, 기존 서비스를 중단하고 새 버전의 sw를 실행해야한다.
내경우에도 새 버전의 docker image를 pull하고 -> 기존 컨테이너를 종료하고 -> 새 버전의 컨테이너를 실행하는 방식이였다.
그렇다면 당연하게도, 서비스가 중단되는 다운타임이 발생한다. 이를 해결하는 방식이 무중단 배포인것이다.
무중단 배포의 종류
무중단배포를 구현하기 위해서 대표적으로 3가지 방식이 통용된다.
Rolling 배포
사용중인 인스턴스들에 새 버전의 서비스를 점진적으로 배포하는 방식이다. 즉, 서비스중인 인스턴스 하나를 로드밸런스에서 라우팅하지 않도록 한 뒤, 새로운 버전의 서비스를 적용하여 다시 라우팅하도록 등록한다. 이를 반복하며 모든 인스턴스에 새 버전의 서비스를 배포한다.
인스턴스마다 차례로 배포를 진행하므로, 새 버전의 인스턴스에서 어떤 이슈가 발생했을 경우 쉽게 롤백이 가능하다는 장점이 있으나, 새 버전 배포중에는 서비스중인 인스턴스 수가 감소하므로 동작중인 인스턴스에 트래픽이 몰릴 수 있다. 또한 진행중엔 기존버전과 새로운 버전이 함께 존재하므로 호환성 문제가 생기기도 한다.
따라서 새 배포에 큰 변화가 없거나, 이미 충분히 테스트한 기능일 경우 사용해야하는 점진적 롤백 방식이다.
Blue-Green 배포
Blue라는 기본버전과 Green이라는 새로운 버전을 따로 운용하는 방식이다. Green에 해당하는 인스턴스들에 신버전을 배포하고, 로드밸런서가 모두 Green의 인스턴스를 바라보도록 전환한다.
구버전의 인스턴스가 남아있어 문제시 빠른 롤백이 가능하다는 장점이 있다. 다만 Blue영역과 Green영역이 따로따로 존재하는것이므로 시스템 자원이 두배 필요해 비용이 더 많이 필요하다는 단점이 있다.
따라서 시스템 자원이 충분한 경우에 사용해야한다. 또한 빠르고 안전한 롤백이 필요한 경우에도 유용하다.
Canary 배포
잠재적 문제 상황을 미리 발견할 수 있는 배포 전략으로, 지정한 서버나 특정 유저에게만 배포했다가 오류가 없다고 판단되면 전체 시스템에 단계적으로 배포하는 방식을 말한다. 즉, 트래픽의 일부만 신버전을 사용하게 한 뒤 오류여부를 확인하는것.
문제상황을 빠르게 감지할 수 있어 성능모니터링에 유용하다는 장점, A/B테스트가 가능하다는 장점이 있다.
그러나 네트워크 트래픽 제어에 부담이 될 수 있다는 단점이 존재한다.
따라서 소수의 사용자에게만 영향을 끼치는 것이므로 안정성이 중요한 금융시스템 등에서 사용한다. 새로운 기능 혹은 실험적 기능을 도입할때 이용함으로써 문제상황을 초기단계에 발견할수도 있다.
cf. 요청 처리중에 앱이 종료된다면?
새버전 배포로 인해 요청 처리중에 있는 인스턴스의를 종료해야하는 상황이 발생할 수 있다.
이때 hard shutdown 과 graceful shutdown이라는 방식이 존재한다. 전자의 경우 spring에서 기본적으로 사용하는 전략으로, 요청 처리중이건 말건 강제 셧다운 하는 방식이다. 후자의 경우 요청처리중이면 이 처리까지 완료되어야 종료되는 방식이다. 이때 기존요청은 완료하지만 새요청은 허용되지 않는 유예기간을 제공한다.
Blue-Green 무중단 배포 적용하기
그렇다면 이러한 방법들중에 뭐가 가장 현재 서버에 적합할까? 고민한 결과, Blue-green 방식이라는 결론을 내렸다.
우선 현재 백엔드 서버 자체가 단 하나의 인스턴스만 갖고있었고, 작은 변화의 배포보단 큰 변화의 배포(버전 2 배포 등)가 이루어질것이였기 때문이다. 또한 문제가 생기면 아주 신속한 롤백이 필요하다고 느꼈다.
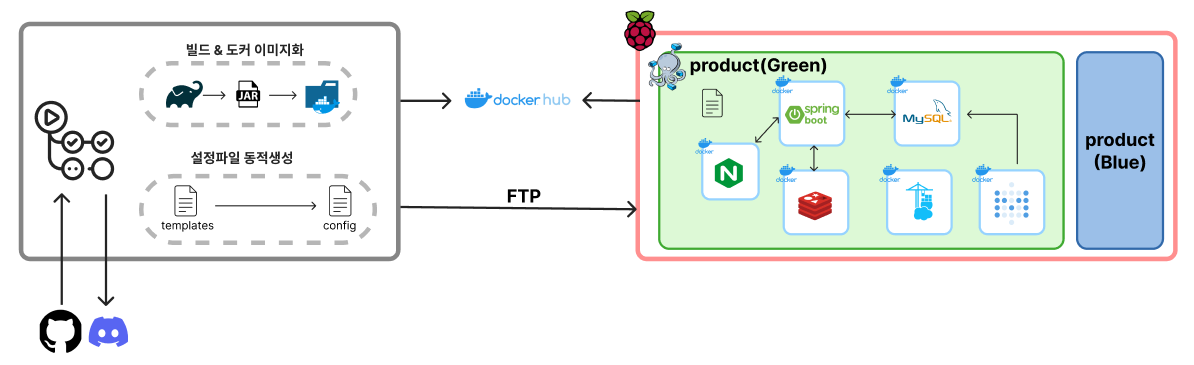
구현을 위해, 두개의 인스턴스를 만들어야했다.
내경우 docker 컨테이너를 app_blue와 app_green으로 분리함으로써 간단하게 구현했다.
services:
app_blue:
image: ${DOCKERHUB_USERNAME}/bbaegok:latest
platform: linux/arm64
ports:
- "8081:8080"
environment:
- ENV=blue
app_green:
image: ${DOCKERHUB_USERNAME}/bbaegok:latest
platform: linux/arm64
ports:
- "8082:8080"
environment:
- ENV=green
그리고 Github Actions의 CI/CD 스크립트에서 deploy 작업을 어떤 컨테이너에 수행할지, 또 어떤 컨테이너를 활성화 시켜둘지 자동으로 수행하도록 해야했다. 쉽게 말해서 기존에 켜져있던게 blue였다면 green컨테이너에 배포 후 실행하고, nginx 트래픽을 green쪽으로 전환해야했다. 따라서 다음과 같은 스크립트를 작성했다.
- name: Deploy Blue-Green to Raspberry Pi
uses: appleboy/ssh-action@master
with:
//..생략
script: |
cd Project/bbaegok/prod/
# 현재 실행중인 app color 확인
if docker ps --filter "name=app_blue" --filter "status=running" | grep app_blue; then
CURRENT="blue"
NEXT="green"
else
CURRENT="green"
NEXT="blue"
fi
echo "Current active app: $CURRENT" #테스트용 echo
echo "Deploying next app: $NEXT" #테스트용 echo
ACTIVE_COLOR=$NEXT envsubst '${ACTIVE_COLOR}' < nginx.conf > nginx_final.conf #nginx 트래픽 라우팅을 active_color로 변경
mv nginx_final.conf nginx.conf
docker-compose pull app_${NEXT}
docker-compose up -d app_${NEXT}
docker-compose up -d --no-deps --build nginx
docker-compose stop app_${CURRENT}# Nginx.conf 설정
location /backend/ {
rewrite ^/backend/(.*) /$1 break;
proxy_pass http://spring_app_${ACTIVE_COLOR}/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
이 방식을 통해서 간단하게 두 컨테이너를 전환하여 Blue-Green 배포를 적용 할 수 있었다.
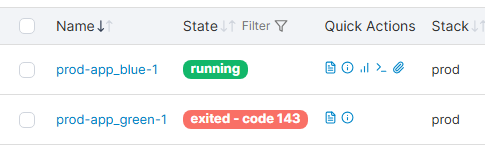
헬스체크(Health Check) 적용하기
이렇게 전환에 성공하면 무중단 배포가 끝난줄 알았지만, 사실 함정 하나가 숨어있었다.
docker-compose pull app_${NEXT} #새버전 이미지 pull
docker-compose up -d app_${NEXT} #새버전 컨테이너 실행
docker-compose up -d --no-deps --build nginx #nginx설정 리로드
docker-compose stop app_${CURRENT} #기존버전 종료
예를들어 Green컨테이너에 새 버전을 배포해서 실행했을경우, Green 컨테이너가 정상적으로 요청을 받을 준비가 되기도 전에 Nignx가 리로드 되면서 트래픽을 넘겨버릴수 있는것이다. 즉, 준비가 안된 백엔드 서버에 요청을 날려버린다!
따라서 이때 전송한 요청들은 실패하게 된다. 그렇다면 진정한 의미의 무중단 배포가 되지 않은것...ㅜㅜ
이를 해결하기 위해 존재하는게 바로 "헬스체크" 인것이다.
개념은 간단하다. 백엔드서버에 /health 요청을 전송했을때 응답이 오면 정상적인 상태이고, 오류가 나면 비정상인것.
이를 위해 해당 API를 직접 만들어도 되지만, Spring의 경우 Spring Boot Actuator라는것이 있어 간단히 사용할 수 있다.
// build.gradle
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-actuator'
}management.endpoint.health.show-details=always
management.endpoints.web.exposure.include=health,info
management.health.redis.enabled=false
management.health.diskspace.enabled=false위와같이 설정 후, http://${spring컨테이너}/actuator/health와 같이 요청하면 {"status":"UP"}와 같은 응답을 반환한다.

따라서 이 API를 활용해서 CI/CD과정에 헬스체크를 추가하면 된다.
script: |
cd Project/bbaegok/staging/
# 현재 실행중인 app color와 포트
if docker ps --filter "name=app_blue" --filter "status=running" | grep app_blue; then
CURRENT="blue"
NEXT="green"
else
CURRENT="green"
NEXT="blue"
fi
if [ "$NEXT" = "blue" ]; then
NEXT_PORT=8090
else
NEXT_PORT=8091
fi
echo "Current active app: $CURRENT"
echo "Deploying next app: $NEXT : $NEXT_PORT"
ACTIVE_COLOR=$NEXT envsubst '${ACTIVE_COLOR}' < nginx.conf > nginx_final.conf
mv nginx_final.conf nginx.conf
# 새 버전 pull 및 앱 컨테이너 실행
docker-compose pull app_${NEXT}
docker-compose up -d app_${NEXT}
# 새 인스턴스에 대한 헬스체크(최대 1분까지 5회 재시도)
for i in {1..12}; do
sleep 5
if curl -fs http://localhost:$NEXT_PORT/actuator/health | grep '"status":"UP"' > /dev/null; then
echo "✅ Health check passed"
break
fi
if [ "$i" -eq 12 ]; then
echo "❌ Health check failed for app_${NEXT}"
# 컨테이너 중지 및 삭제 (optional)
docker-compose stop app_${NEXT}
docker-compose rm -f app_${NEXT}
# 실패 알림용 파일 생성
echo "DEPLOY_FAILED" > .deploy_status
exit 1
fi
done
# nginx에 새 color 적용
ACTIVE_COLOR=$NEXT envsubst '${ACTIVE_COLOR}' < nginx.conf > nginx_final.conf
mv nginx_final.conf nginx.conf
docker-compose up -d --no-deps --build nginx
# 5. 기존 컨테이너 종료
docker-compose stop app_${CURRENT}
헬스체크에서 조심해야 하는점
Spring Boot Actuator 헬스 체크의 동작원리를 잘 모르고 사용하면 문제가 일어날 수 있다. 사실 이 라이브러리의 첫인상은 단순히 헬스체크용 API를 하나 만들어주는것 뿐인데 왜 문제가 생기지..? 하는 의구심이 있었다.
이부분을 공부하며 참고한 글은 토스 테크 블로그의 SpringBoot Actuator의 헬스체크 살펴보기이다.
핵심적인 문제를 정리하자면 다음과 같다.
(1) 의도치 않은 장애 발생
Actuator는 여러 HealthIndicator의 상태를 종합해서 판단한다. 따라서 로그DB처럼 서비스에 영향없는 요소가 DOWN 상태일경우 전체상태를 DOWN으로 판단할 수 있다. 결국 로드밸런서는 이 상태를 읽고 트래픽을 차단해버리고, 서비스 DB는 멀쩡한데도 장애로 동작하게 되는것이다.
이를 해결하기 위해서는
- /actuator/health 대신 직접 구현한 HealthCheck를 사용
- 필요없는 healthIndicator를 비활성화(management.health.db.enabled=false) or 커스터마이징
하는 방법이 있다.
(2) 트러블 슈팅 지연
위 내용과 비슷하게, 외부 의존성(ex. Redis, Elasticsearch)이 죽으면 Actuator도 함께 DOWN을 반환한다. WAS는 정상인데 LB를 거치면 접속이 안되어 문제파악이 늦어지는것이다. 결국 이러한 원인을 찾지 못해 불필요한 디버깅을 하게되어 시간낭비를 유발하는것!
해결방법은 다음과 같다.
- 헬스체크 상세 정보를 로그로 확인
- 헬스체크 동작 원리 정확히 파악
- 평소에도 각 인스턴스의 헬스체크 직접 호출해보기
결론적으로 Actuator는 매우 편리하고 똑똑한 도구지만, 잘못쓸경우 잘못된 장애를 유발할 수 있으니 적절히 구성해야한다는 것이다. 내 서버에서도 Redis를 쓰고 있기때문에 이부분에서 DOWN이 발생할경우 헬스체크API가 DOWN을 유발해 장애를 발생시킬 수도 있을것이라고 예측했다(SpringBoot Actuator는 자동으로 프로젝트 라이브러리를 스캔한 뒤 관련 HealthIndicator를 자동등록한다).
그래서 다음과같이 헬스체크를 최소화 하는 방식을 활용하여 구성함으로써 문제를 예방하고자 했다.
management.health.redis.enabled=false
management.health.diskspace.enabled=false
추가적으로, 외부에서 해당 요청을 하는것을 막기위해(헬스체크는 어차피 서버 내부에서 직접 진행) 의심경로 차단 스니펫에 경로를 추가해뒀다.(Nginx단에서 바로 403을 응답하게 한다)
# 의심 경로 접근 차단(정찰 경로)
location ~* /(phpinfo|actuator|solr|portal|redlion|druid|manager|systembc|\.aws|\.docker) {
return 403;
}
이를통해 무중단 배포를 안전하게 구성하는데 성공했다! 😀
단순히 돌아가기만 하는 배포를 적용하는데 그치지 않고, 헬스체크와 같이 보다 안정적인 방식을 고민하고, 또 이로인한 문제가 발생하지 않을지를 확인하는 경험을 통해 조금 더 성장한 느낌이 든다.
결론적로... 배포에서 생길 장애상황을 미리 예방하고, 또 문제가 생기더라도 트러블슈팅을 적절히 진행할 수 있도록 구조화하는것의 중요성을 느꼈다ㅎㅎ