과거 첫 웹개발을 배웠을땐 MyBatis로 백엔드를 개발했었다. DB와 데이터를 주고 받으려면 VO와같은 객체를 정의해두고, SQL문을 작성하는 방식이다. 다만 그 과정에서, 간단한 select문들도 매번 새로 정의해주는점이 불편하게 느껴졌고, 무엇보다 VO를 계속해서 만들다보니 이게 과연 객체지향적인 설계인가에 대한 고민이 생겼다.
그래서 조사한 결과, SQL Mapper인 MyBatis와는 달리, ORM으로 작동하는 JPA가 이러한 비효율을 해결해줄 수 있음을 알게되었었다. 백엔드단에 테이블 정보를 객체로 매핑함으로써, 기존의 SQL중심적 개발에서 객체중심의 개발로 전환할 수 있게 된 것이다! 이는 어마어마한 장점을 가져오는데, 개발 생산성과 유지보수에서 아주 큰 이점을 가진다.
특히 JpaRepository를 함께 사용하게 되면 간단한 네이밍 메소드만으로도 SQL쿼리를 날릴 수 있었고, 어려운 동적쿼리의 경우도 QueryDSL을 함께 사용함으로써 간단히 구현할 수 있었다. 아, 귀찮았던 페이징도 Pageable 객체를 통해 손쉽게 구현할 수 있다.
이러한 이유로 JPA를 배운 후론 2년이 넘게 주로 사용하고있다. 대세 기술(?!)으로 소문이 나서인지, SSAFY에서도 교육과정에서 배우는건 MyBatis였지만 프로젝트에선 다들 JPA를 사용하고 싶어 하더라.ㅎㅎ 그러나 영속성의 개념, 연관관계의 개념으로 인해 러닝커브가 높았기에 엔티티설계와 같은 부분은 내가 도맡아서 했었다. 이 과정에서 엔티티에 대해 좀더 딥하게 공부할 수 있었는데, 초보자가 쉽게 착각할만한 부분에 대해 알게되었다.
그게 바로 오늘 포스팅의 주제, <JPA 엔티티 객체지향적으로 설계하기> 이다. 부제는 <테이블과 일대일 매핑은 그만> 정도가 되겠다.
오늘의 주제와 가장 적합했던 프로젝트는, 대전광역시 공공데이터 활용 창업 경진대회에 참가하면서 개발했던 <Findog>인것같다. 간단히 소개하자면 비문인식AI, 안면인식AI를 통해서 실종 반려견을 찾아주는 어플이다. 페르소나는 전국의 유기동물 보호소, 유기견 임시보호자, 그리고 실종 반려견의 주인이다.
따라서 필요한 데이터 테이블또한 간단하게 설정된다.
실종된 강아지 정보, 임시보호중인 강아지 정보, 보호소에 등록된 강아지 정보, 개인회원, 기업회원 정보가 필요하다.
앞의 세개 강아지 정보엔 공통적인 속성이 있었기 때문에, 정규화를 통해 공통테이블(강아지)로 분리했다.

자, 이제 이 테이블에 기반한 엔티티를 설계해보도록 하자.
바로 이순간, 초보자때 가장 실수하기 쉬운 부분이 있다. 바로 테이블과 엔티티를 단순 일대일 매핑하는것이다. 즉, 6개 엔티티가 그대로 나올것이다. 어쩌면 Dog엔티티와 나머지 세가지 강아지 엔티티에 연관관계를 만들어버릴수도 있다.
물론 이렇게 해도 충분히 개발할 수 있다.
그러나 위와같은 설계는 몇가지 중복코드를 불러온다. 작성일 데이터나 주소데이터, 두 유형의 회원간 동일 데이터가 그 예시이다. JPA의 가장 큰 장점인 SQL과의 패러다임 불일치를 해결하고, 생산성을 극대화 하려면, 일명 '결합도는 낮추고 응집성은 높인' 설계가 필요하다. 이를 위해선 어떻게 해야하는가?
우선 결과부터 소개하고, 자세히 설명하도록 하겠다.

@Inheritance를 활용한 상속관계 매핑, abstract와 @MappedSuperClass를 활용한 매핑정보 상속, @Embeddable을 활용한 값타입 매핑 등이 있다.
하나씩 자세히 보도록 하자!
@Inheritance를 활용한 상속관계 매핑하기

우선, RDB의 슈퍼타입-서브타입 관계를 구현하기 위해서는 객체의 상속, 즉 extends를 활용한다.
Dog라는 부모클래스를 만들고 속성을 확장했다. 실종,임시보호견,보호소견이 자식클래스가 되는것이다.
이 과정에서 주의할것이, 자바단의 상속과 RDB의 슈퍼타입 관계를 매핑하는 방식엔 세가지 전략이 있다는것.
- JOINED : 조인전략 (부모테이블에 DTYPE과 함께 저장, 각 자식테이블에 부모테이블 ID를 저장)
- SINGLE_TABLE : 단일 테이블 전략 (부모테이블에 모든 데이터를 저장, DTYPE으로 구분)
- TABLE_PER_CALSS : 구현 클래스마다 테이블전략 (부모테이블 없이 자식테이블에 데이터 각각 저장)
3번은 DB나 ORM단에서 둘다 이점이 없으므로, 1번이나 2번을 사용해야한다. 다만 2번은 앞으로 확장할 일이 없는 테이블일때 추천한다고 한다. 따라서 대부분은 1로 작성하면 된다. FINDOG에서는 세가지 반려견 종류 말고도 다른 종류(민간 보호소)가 확될 수 있으리라는 판단 하에, 1번 전략을 선택했다.
따라서 Dog 엔티티는 다음과같이 만들어진다.
@Entity
@Table(name = "dog")
@Inheritance(strategy = InheritanceType.JOINED)
@DiscriminatorColumn(name = "dtype", discriminatorType = DiscriminatorType.STRING)
public abstract class Dog {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
protected Long dogId;
//..생략
또한, 위 부모 엔티티를 상속받는 자식 엔티티는 다음과같이 만들어진다.
@Getter @ToString
@Entity
@DiscriminatorValue("SHELTER")
@Table(name = "shelter_dog")
public class ShelterDog extends Dog {
private String noticeNo;
//..생략
@DiscriminatorValue가 바로 DTYPE에 들어갈 구분값이 된다.
이렇게 RDB 설계시의 슈퍼타입-서브타입 형식을 객체의 상속으로 매핑 할 수 있다. 두 방식의 패러다임 불일치 문제를 해결하는 대표적 방식중 하나인것이다. 상속된 필드와 메소드를 사용할 수 있음은 물론, 오버라이딩을 통해 각 자식객체에 맞게 작동방식의 변경도 가능해진다.
@MappedSuperClass를 활용한 매핑정보 상속
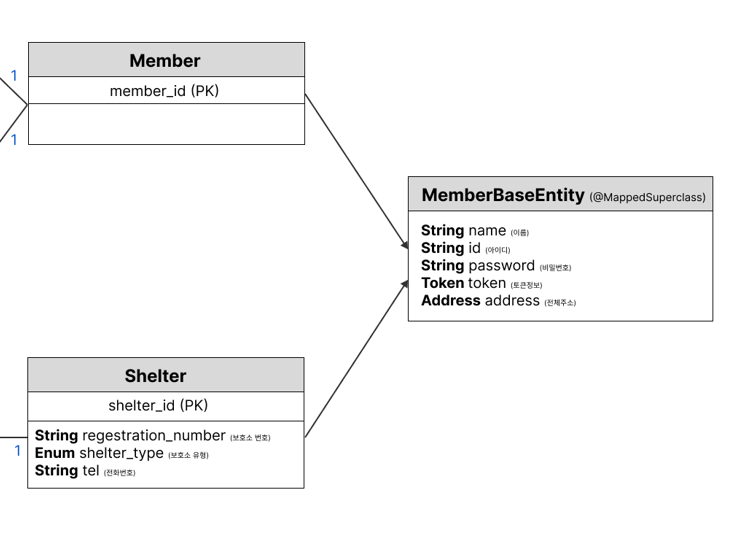
Member(일반회원)와 Shelter(기업회원)은 서로 다른 테이블을 가지지만, 사실 '유저'라는 점에서 같은내용의 필드를 가진다. 즉, 공통속성을 가지는데 이 공통속성이 테이블을 갖지는 않는다. 이럴경우 @MappedSuperClass를 쓴다. 테이블과 관계없이 단순히 엔티티가 공통으로 사용하는 매핑정보를 모으는 역할이다.
엔티티는 같은 엔티티 또는 @MappedSuperClass로 지정한 클래스만 상속받을 수 있기에, 테이블이 존재한다면 아까와같이 @Inheritance를, 단순 공통속성만 받고싶다면 @MappedSuperClass를 쓰면 된다.
따라서 나는 MemberBaseEntity라는 공통속성을 분리하고, @MappedSuperClass를 abstract로 선언함으로써 Member와 Shelter엔티티를 간단히 구현했다.
@MappedSuperclass
public abstract class MemberBaseEntity implements UserDetails {
@Column(nullable = false)
protected String name;@Entity
@Table(name = "shelter")
public class Shelter extends MemberBaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long shelterId;
이를통해 가질 수 있는 장점은 명확해보인다. 이 앱에서 사용자들의 name을 nickname으로 바꾸고싶다면? 원래는 Shelter와 Member 클래스에 각각 들어가 하나씩 내용을 바꿔줘야 했을것이다. 메소드까지 전부 바꾸려면 꽤나 반복작업이 많았을것이다.
그러나 @MemberBaseEntity를 사용함으로써, 이 클래스 내의 내용만 바꿔주면 간단히 전부 교체된다! 서로 아예 관계가 없는 엔티티일지라도 매핑정보를 공유할 수 있는 가장 좋은 방법이다.
@Embeddable을 활용한 값타입 매핑

마지막으로, 값타입을 활용한 매핑이다.
엔티티를 설계하다보면, 임베디드 타입이라는 복합 값타입이 필요한 상황이 생긴다.
예를들어, 주소라는 정보는 나라정보, 우편번호, 도로명주소, 세부주소를 포함할 수 있다. 그렇가면 주소를 필요로 하는 모든 엔티티 객체에 이 네가지 정보를 전부 적어줘야할까? 그렇다면 이 네가지 값들로 인해 생기는 메소드, 예를들어 getFullAddress()같은것도 매번 선언해줘야할까?
이럴때 @Embeddable을 통해 간편하게 해결 할 수 있다. 내경우엔 Address 뿐만 아니라 CrudDate와 같은 생성일, 그리고 Token정보까지 값타입으로 만들었다. 필요한 필드들과 메소드까지 전부 정의해두고, 이를 엔티티들에 필드로 임베딩함으로써 모두 같은 필드와 메소드를 사용 할 수 있게 되는 것이다. 참고로, 당연히 이 임베드 타입들은 따로 테이블로 생성되지 않는다!
@Embeddable
public class Address {
private String address1;
private String address2;
값타입을 선언할땐 @Embeddable을 사용하고,
@Getter @ToString
@MappedSuperclass
public abstract class MemberBaseEntity implements UserDetails {
//..생략
@Embedded
protected Token token;
@Embedded
protected Address address;
값타입을 사용할땐 @Embedded를 사용한다.
이를 통해 가질 수 있는 가장 눈에 띄는 이점은 바로 응집도와 재사용이다. Address에 관한 수정사항이 있다면 바로 해당 값타입 클래스로 들어가서 수정하면 되므로 유지보수에 큰 장점이며, 차후 다른 엔티티에서 사용하기에도 편리하다.
특히, Period.isWork()와 같이 해당 값타입만 사용하는 의미있는 메소드를 만들 수 있다.
굉장히 객체지향적인 코드를 짤 수 있는것이다 😉
잘 설계한 ORM은 매핑한 테이블보다 클래스의 수가 더 많다.
엔티티를 설계할땐 항상 위 내용을 고려하면서 설계하려고 노력한다. 매핑한 테이블과 클래스의 수가 같다면.. 동작은 하지만 객체지향적인 설계는 아닐 확률이 크다. '객체지향'이란 현실세계를 객체로 반영한것인 만큼, 클래스로 묶을 수 있는것은 @Embeddable로 묶어보고, 같은 내용의 반복이 있다면 @MappedSuperClass를 고려해보고, 이것이 만약 상속구조를 가질만한 구조라면 @Inheritance까지 도입해보면 좋을것이다.
관련 코드는 이 레포지토리에서 볼 수 있다!